
This is part 3 of a series on “Handling Categorical Data in R” where we are learning to read, store, summarize, reshape & visualize categorical data.
Below are the links to the other articles of this series:
- Part 1 - Introduction to Factor
- Part 2 - Summarize Categorical Data
- Part 4 - Visualize Categorical Data
In this article, we will learn to manipulate/reshape categorical data by changing the value and order of levels/categories.
Table of Contents
Resources
You can download all the data sets, R scripts, practice questions and their solutions from our GitHub repository.
Introduction
In this section, our focus will be on handling the levels of a categorical variable, and exploring the forcats package for the same. We will basically look at 3 key operations or transformations we would like to do when it comes to factors which are:
- change value of levels
- add or remove levels
- change order of levels
Before we start working with the value of the levels, let us read the case study data and take a quick look at some of the functions we used in the previous articles.
# read data
data <- readRDS('analytics.rds')We will store the source of traffic as channel instead of referring to the column in the data.frame every time.
channel <- data$channelLet us go back to the function we used for tabulating data, fct_count(). If you observe the result, it is in the same order as displayed by levels().
fct_count(channel)## # A tibble: 8 x 2
## f n
## <fct> <int>
## 1 (Other) 6073
## 2 Affiliates 7388
## 3 Direct 39853
## 4 Display 3375
## 5 Organic Search 139668
## 6 Paid Search 4395
## 7 Referral 35615
## 8 Social 8031If you want to sort the results by the count i.e. most common level comes at the top, use the sort argument.
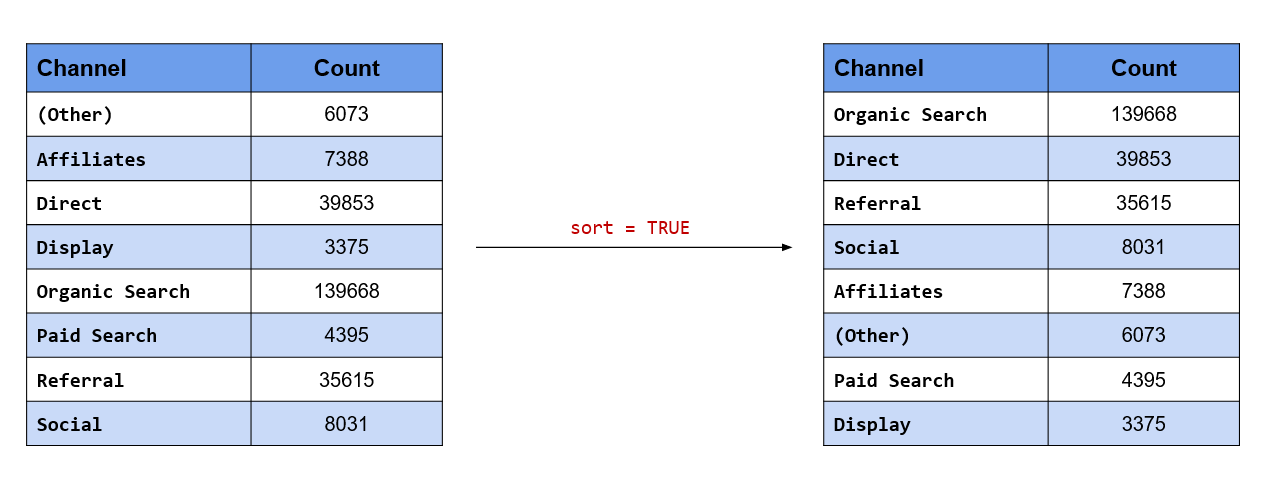
fct_count(channel, sort = TRUE)## # A tibble: 8 x 2
## f n
## <fct> <int>
## 1 Organic Search 139668
## 2 Direct 39853
## 3 Referral 35615
## 4 Social 8031
## 5 Affiliates 7388
## 6 (Other) 6073
## 7 Paid Search 4395
## 8 Display 3375If you want to view the proportion along with the count, set the prop argument to TRUE.
fct_count(channel, prop = TRUE)## # A tibble: 8 x 3
## f n p
## <fct> <int> <dbl>
## 1 (Other) 6073 0.0248
## 2 Affiliates 7388 0.0302
## 3 Direct 39853 0.163
## 4 Display 3375 0.0138
## 5 Organic Search 139668 0.571
## 6 Paid Search 4395 0.0180
## 7 Referral 35615 0.146
## 8 Social 8031 0.0329One of the important steps in data preparation/sanitization is to check if the levels are valid i.e. only levels which should be present in the data are actually present. fct_match() can be used to check validity of levels. It returns a logical vector if the level is present and an error if not.
table(fct_match(channel, "Social"))##
## FALSE TRUE
## 236367 8031Change Value of Levels
In this section, we will learn how to change the value of the levels. In order to keep it interesting, we will state an objective from our case study and then map it into a function from the forcats package.
Combine both Paid & Organic Search into a single level, Search
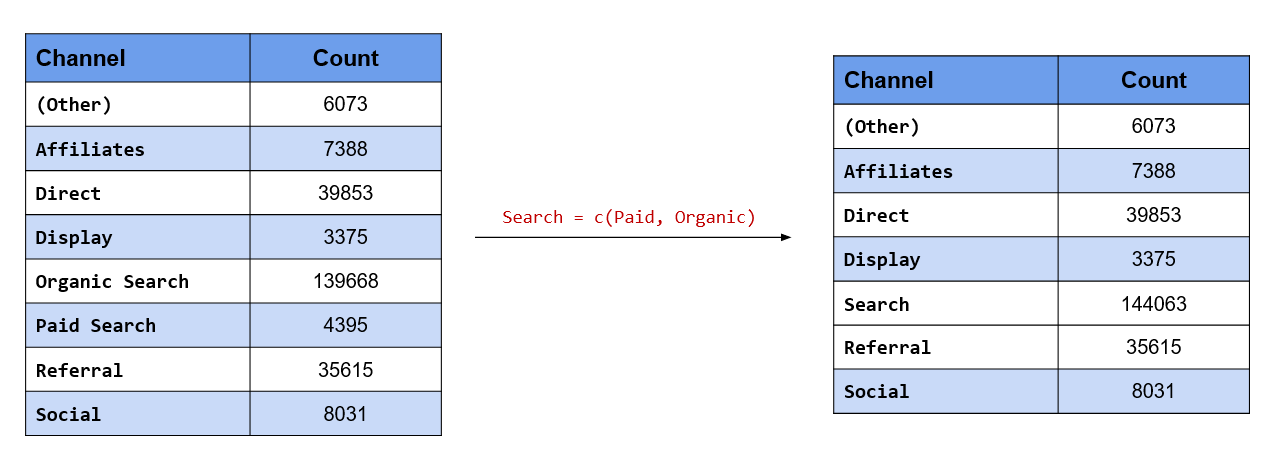
In this case, we want to change the value of two levels, Paid Search & Organic Search and give them the common value Search. You can also look at it as collapsing two levels into one. There are two functions we can use here:
fct_collapse()fct_recode()
Let us look at fct_collapse() first. After specifying the categorical variable, we specify the new value followed by a character vector of the existing values. Remember, the new value is not enclosed in quotes (single or double) but the existing values must be a character vector.
fct_count(
fct_collapse(
channel,
Search = c("Paid Search", "Organic Search")
)
)## # A tibble: 7 x 2
## f n
## <fct> <int>
## 1 (Other) 6073
## 2 Affiliates 7388
## 3 Direct 39853
## 4 Display 3375
## 5 Search 144063
## 6 Referral 35615
## 7 Social 8031In the case of fct_recode(), each value being changed must be specified in a new line. Similar to
fct_collapse(), the new value is not enclosed in quotes but the existing values must be.

fct_count(
fct_recode(
channel,
Search = "Paid Search",
Search = "Organic Search"
)
)## # A tibble: 7 x 2
## f n
## <fct> <int>
## 1 (Other) 6073
## 2 Affiliates 7388
## 3 Direct 39853
## 4 Display 3375
## 5 Search 144063
## 6 Referral 35615
## 7 Social 8031Retain only those channels which have driven a minimum traffic of 5000 to the website
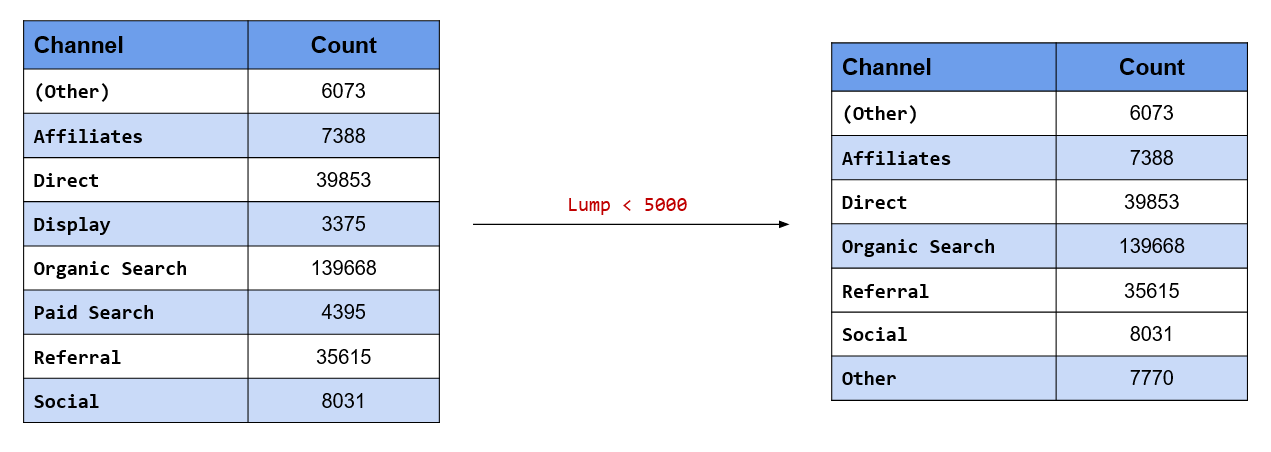
Instead of having all the channels, we desire to retain only those channels which have driven at least 5000 visits to the website. What about the rest of the channels which have driven less than 5000? We will recategorize them as Other. Keep in mind that we already have a (Other) level in our data. fct_lump_min() will lump together all levels which do not have a minimum count specified. In our case study, only Display drives less than 5000 visits and it will be categorized into Other.
fct_count(fct_lump_min(channel, 5000))## # A tibble: 7 x 2
## f n
## <fct> <int>
## 1 (Other) 6073
## 2 Affiliates 7388
## 3 Direct 39853
## 4 Organic Search 139668
## 5 Referral 35615
## 6 Social 8031
## 7 Other 7770Retain only top 3 referring channels and categorize rest into Other
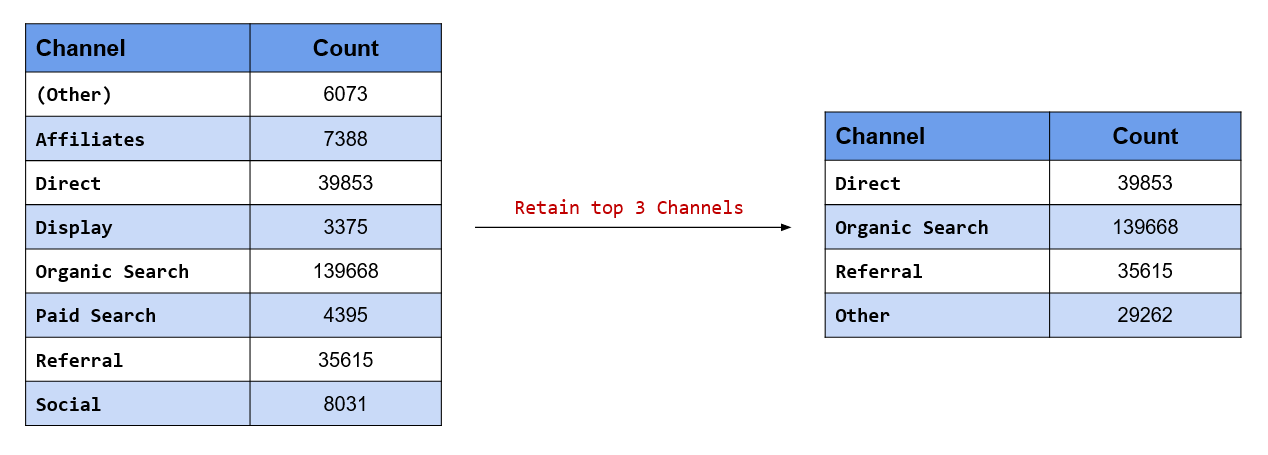
Suppose you decide to retain only the top 3 channels in terms of the traffic driven to the website. In our
case study, these are Direct, Organic Search and Referral. We want to retain these 3 levels and categorize the rest as Other. fct_lump_n() will retain top n levels by count/frequency and lump the rest into Other.
fct_count(fct_lump_n(channel, 3))## # A tibble: 4 x 2
## f n
## <fct> <int>
## 1 Direct 39853
## 2 Organic Search 139668
## 3 Referral 35615
## 4 Other 29262In our case, n is 3 and hence the top 3 channels in terms of traffic driven are retained while the rest are
lumped into Other.
Retain only those channels which have driven at least 2% of the overall traffic
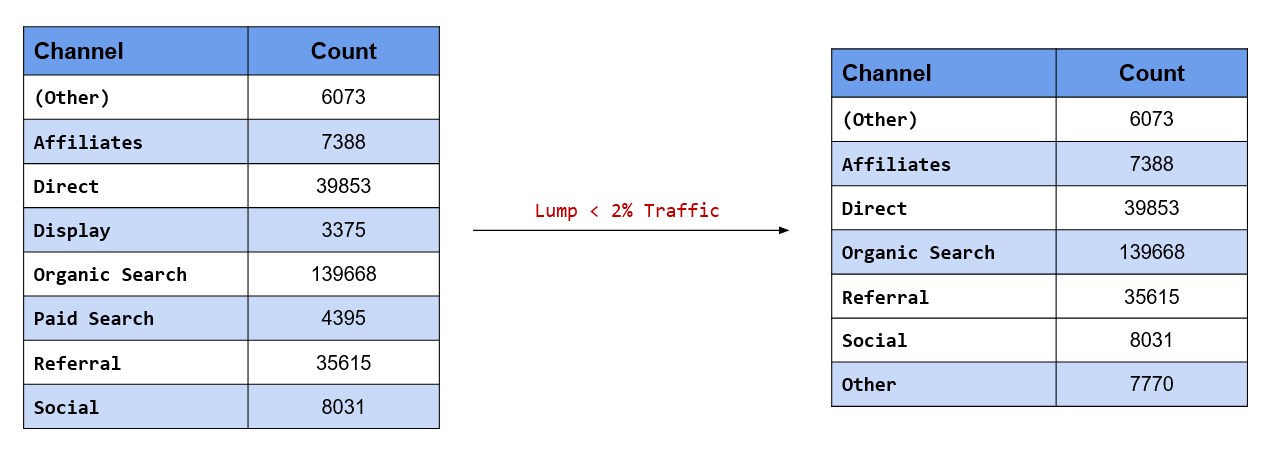
In the second scenario above, we retained channels based on minimum traffic driven by them to the website.
The criteria was count of visits. If you want to specify the criteria as a percentage or proportion instead of count, use fct_lump_prop(). The criteria is a value between 0 and 1. In our case study, we want to retain channels that have driven at least 2% of the overall traffic. Hence, we have specified the criteria as 0.02.
fct_count(fct_lump_prop(channel, 0.02))## # A tibble: 7 x 2
## f n
## <fct> <int>
## 1 (Other) 6073
## 2 Affiliates 7388
## 3 Direct 39853
## 4 Organic Search 139668
## 5 Referral 35615
## 6 Social 8031
## 7 Other 7770As you can see, only Display drives less than 2% of overall traffic and has been lumped into Other.
Retain the following channels and merge the rest into Other
- Organic Search
- Direct
- Referral
In the previous scenarios, we have been retaining or lumping channels based on some criteria like count or
percentage of traffic driven to the website. In this scenario, we want to retain certain levels by specifying
their labels and combine the rest into Other. While we can use fct_collapse() or fct_recode(), a more
appropriate function would be fct_other(). We will do a comparison of the three functions in a short while.
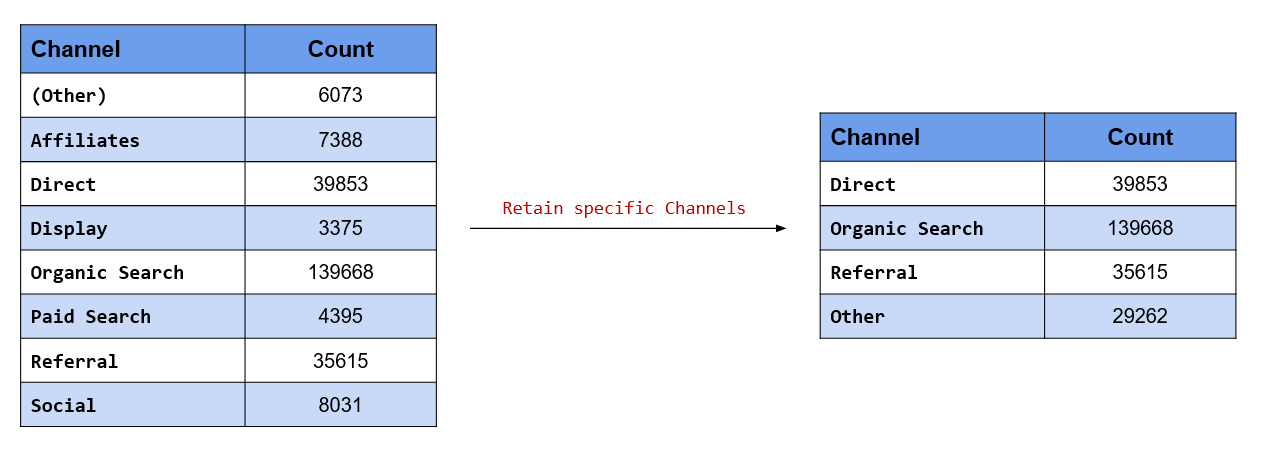
fct_other() has two arguments, keep and drop. keep is used when we know the levels we want to retain
and drop is used when we know the levels we want to drop. In this scenario, we know the levels we want to
retain and hence we will use the keep argument and specify them. Organic Search, Direct and Referral will be retained while the rest of the channels will be lumped into Other.
fct_count(
fct_other(
channel,
keep = c("Organic Search", "Direct", "Referral"))
)## # A tibble: 4 x 2
## f n
## <fct> <int>
## 1 Direct 39853
## 2 Organic Search 139668
## 3 Referral 35615
## 4 Other 29262Merge the following channels into Other and retain rest of them:
- Display
- Paid Search
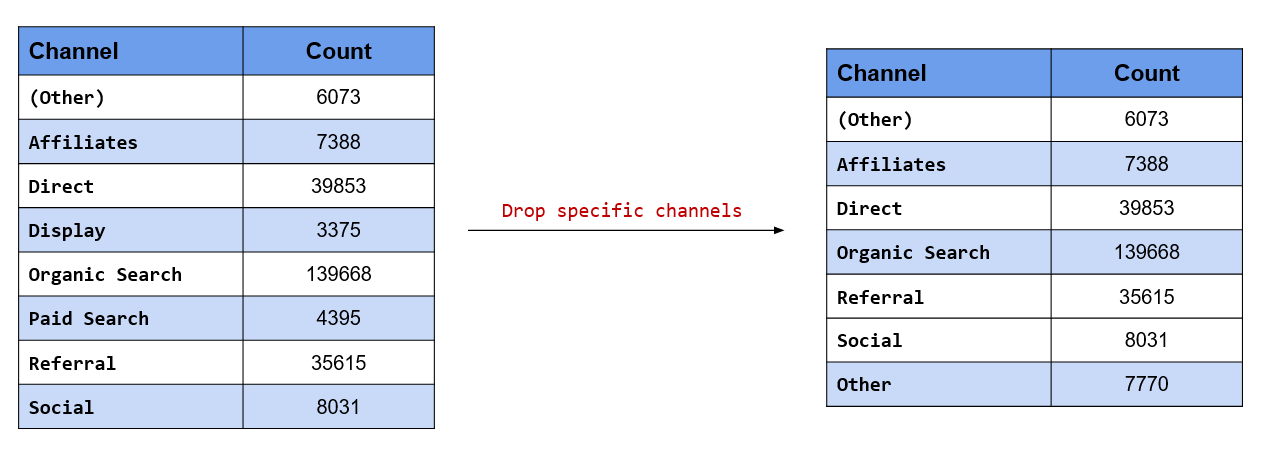
In this scenario, we know the levels we want to drop and hence we will use the drop argument and specify
them. Display and Paid Search will be lumped into Other while the rest of the channels will be retained.
fct_count(
fct_other(
channel,
drop = c("Display", "Paid Search")
)
)## # A tibble: 7 x 2
## f n
## <fct> <int>
## 1 (Other) 6073
## 2 Affiliates 7388
## 3 Direct 39853
## 4 Organic Search 139668
## 5 Referral 35615
## 6 Social 8031
## 7 Other 7770In the previous scenario, we said we will compare fct_other() with fct_collapse() and fct_recode(). Let us use the other two functions as well and see the difference.
# collapse
fct_count(
fct_collapse(
channel,
Other = c("(Other)", "Affiliate", "Display", "Paid Search", "Social")
)
)## Warning: Unknown levels in `f`: Affiliate## # A tibble: 5 x 2
## f n
## <fct> <int>
## 1 Other 21874
## 2 Affiliates 7388
## 3 Direct 39853
## 4 Organic Search 139668
## 5 Referral 35615# recode
fct_count(
fct_recode(
channel,
Other = "(Other)",
Other = "Affiliate",
Other = "Display",
Other = "Paid Search",
Other = "Social"
)
)## Warning: Unknown levels in `f`: Affiliate## # A tibble: 5 x 2
## f n
## <fct> <int>
## 1 Other 21874
## 2 Affiliates 7388
## 3 Direct 39853
## 4 Organic Search 139668
## 5 Referral 35615As you can observe, fct_other() requires less typing and is easier to specify.
Anonymize the data set before sharing it with your colleagues
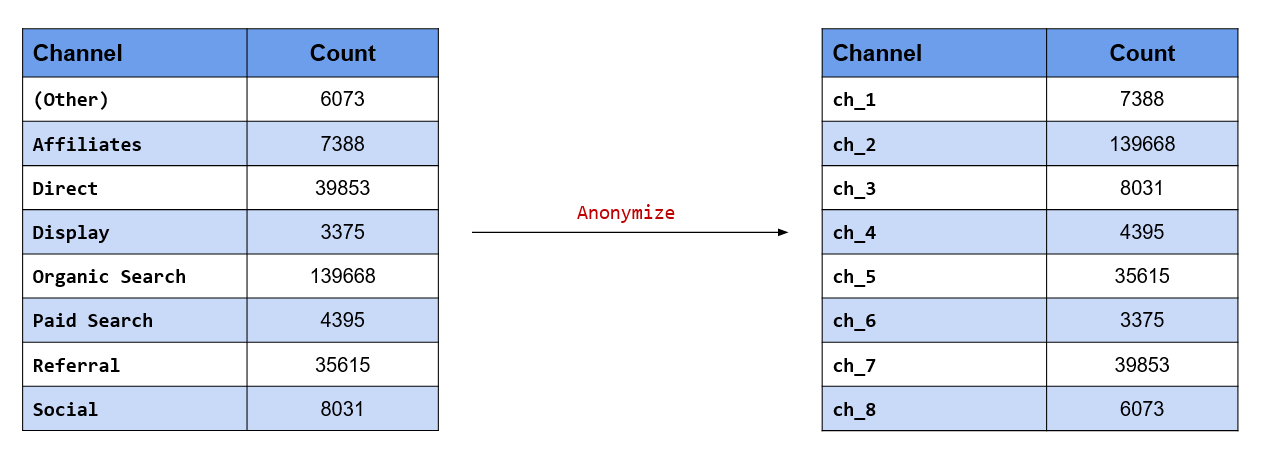
Anonymizing data is extremely important when you are sharing sensitive data with others. Here, we want
to anonymize the channels which drive traffic to the website so that we can share it with others without
divulging the names of the channels. fct_anon() allows us to anonymize the levels in the data. Using the
prefix argument, we can specify the prefix to be used while anonymizing the data.
fct_count(fct_anon(channel, prefix = "ch_"))## # A tibble: 8 x 2
## f n
## <fct> <int>
## 1 ch_1 6073
## 2 ch_2 8031
## 3 ch_3 4395
## 4 ch_4 39853
## 5 ch_5 139668
## 6 ch_6 3375
## 7 ch_7 35615
## 8 ch_8 7388Key Functions
| Function | Description |
|---|---|
fct_collapse()
|
Collapse factor levels |
fct_recode()
|
Recode factor levels |
fct_lump_min()
|
Lump factor levels with count lesser than specified value |
fct_lump_n()
|
Lump all levels except the top n levels |
fct_lump_prop()
|
Lump factor levels with count lesser than specified proportion |
fct_lump_lowfreq()
|
Lump together least frequent levels |
fct_other()
|
Replace levels with Other level |
fct_anon()
|
Anonymize factor levels |
Add / Remove Levels
In this small section, we will learn to:
- add new levels
- drop levels
- make missing values explicit
Add a new level, Blog
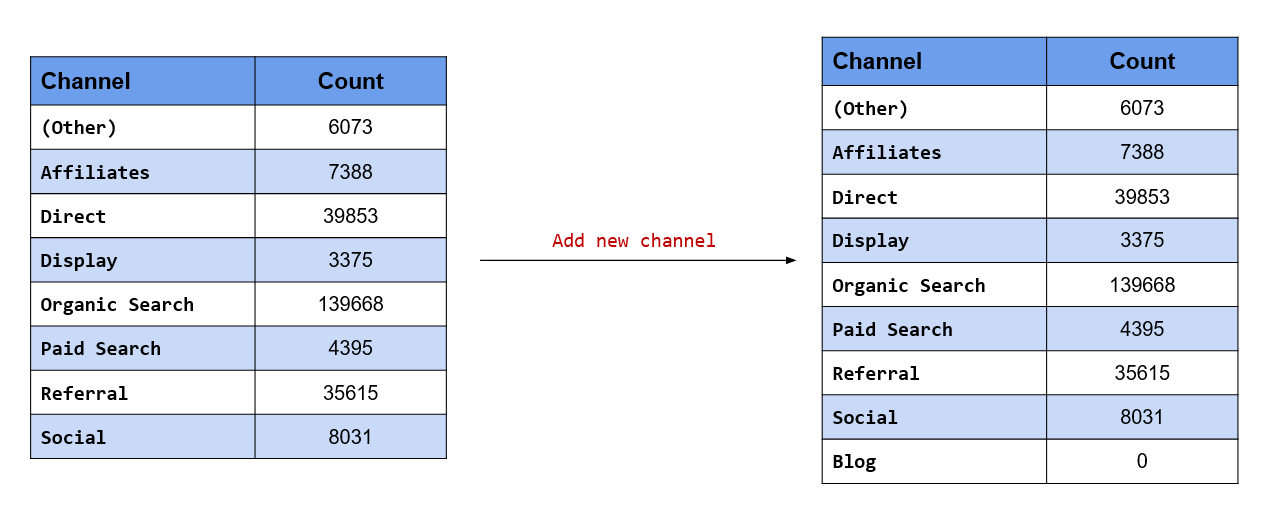
fct_expand() allows us to add new levels to the data. The label of the new level must be specified after the variable name and must be enclosed in quotes. If the level already exists, it will be ignored. Let us add a new level, Blog.
levels(fct_expand(channel, "Blog"))## [1] "(Other)" "Affiliates" "Direct" "Display"
## [5] "Organic Search" "Paid Search" "Referral" "Social"
## [9] "Blog"Drop existing level
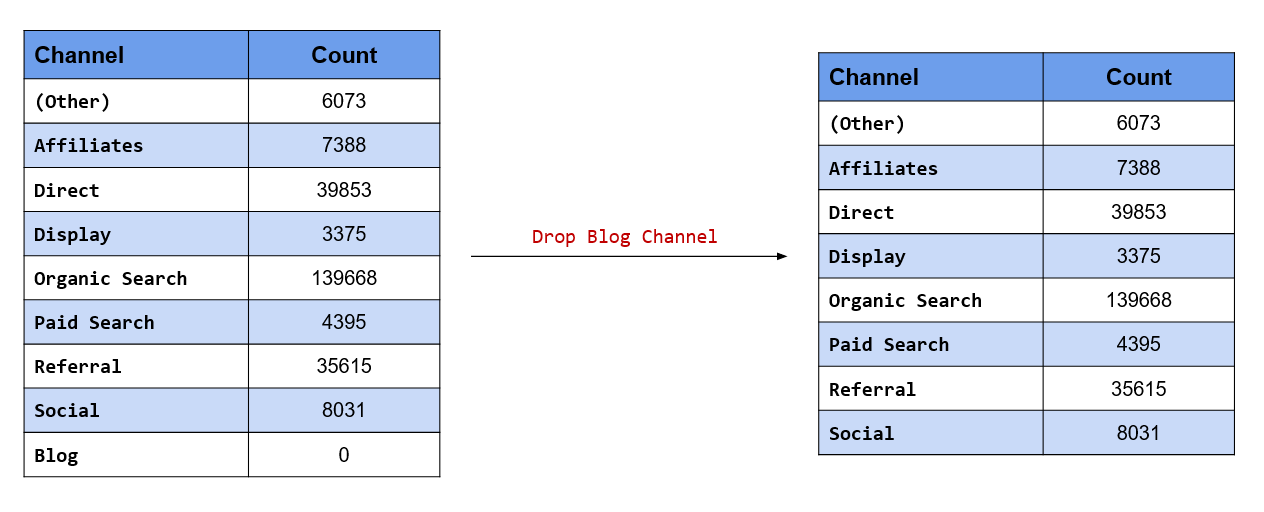
On the other hand, fct_drop() will drop levels which have no values i.e. unused levels. If you want
to drop only specific levels, use the only argument and specify the name of the level in quotes. Let us drop the new level we added in the previous example.
levels(fct_drop(fct_expand(channel, "Blog")))## [1] "(Other)" "Affiliates" "Direct" "Display"
## [5] "Organic Search" "Paid Search" "Referral" "Social"Make missing values explicit

In our data set, the gender column has many missing values, and in R, missing values are represented by NA. Suppose you are sharing the data or analysis with someone who is not an R user, and does not know what NA represents. In such a scenario, we can use the fct_explicit_na() function to make the missing values in the gender column explicit i.e. it will appear as (Missing) instead of NA. This will help non R users to understand that there are missing values in the data.
fct_count(fct_explicit_na(data$gender))## # A tibble: 3 x 2
## f n
## <fct> <int>
## 1 female 40565
## 2 male 61617
## 3 (Missing) 142216Key Functions
| Function | Description |
|---|---|
fct_expand()
|
Add additional levels to a factor |
fct_drop()
|
Drop unused factor levels |
fct_explicit_na()
|
Make missing values explicit |
Change Order of Levels
In this last section, we will learn how to change the order of the levels. We will look at the following scenarios from our case study:
We want to make
- Organic Search the first level
- Referral the third level
- Display the last level
Make Organic Search the first level
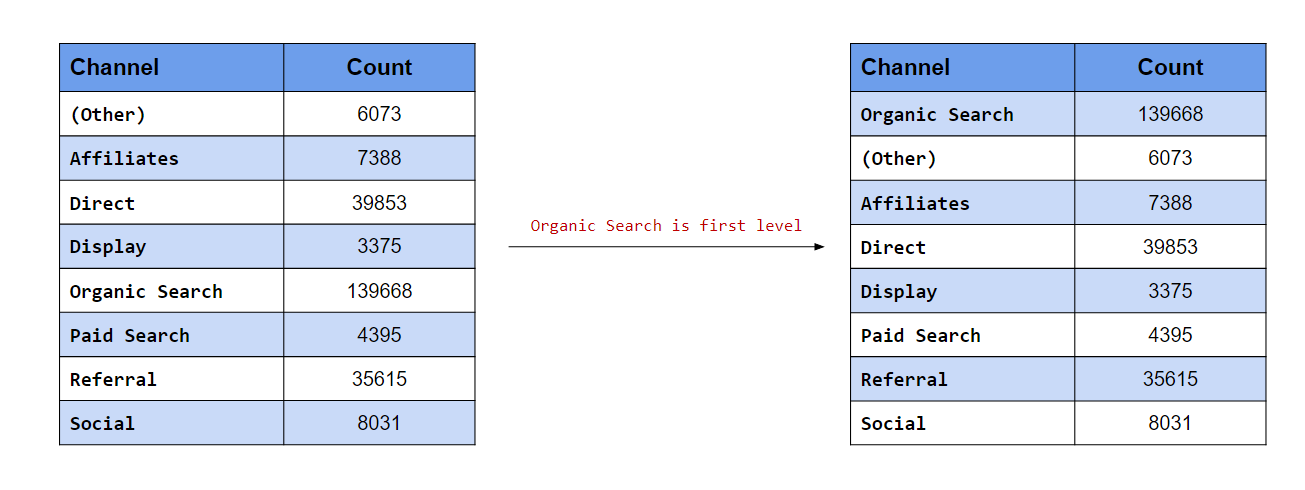
In this scenario, we want the levels to appear in a certain order. In the first case, we want Organic Search to be the first level. fct_relevel() allows us to manually reorder the levels. To move a level to the beginning, specify the label (it must be enclosed in quotes).
levels(channel)## [1] "(Other)" "Affiliates" "Direct" "Display"
## [5] "Organic Search" "Paid Search" "Referral" "Social"levels(fct_relevel(channel, "Organic Search"))## [1] "Organic Search" "(Other)" "Affiliates" "Direct"
## [5] "Display" "Paid Search" "Referral" "Social"Make Referral the third level
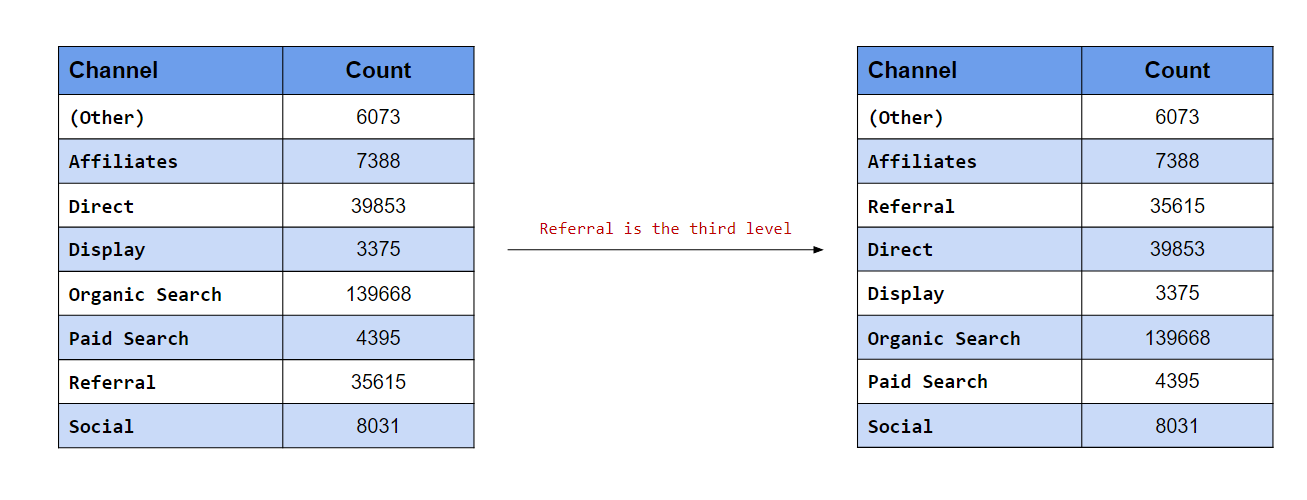
The after argument is useful when we want to move the level to the end or anywhere between the beginning and end. In the second case, we want Referral to be the third level. After specifying the label, use the after argument and specify the level after which Referral should appear. Since we want to move it to the third position, we will set the value of after to 2 i.e. Referral should come after the second position.
levels(channel)## [1] "(Other)" "Affiliates" "Direct" "Display"
## [5] "Organic Search" "Paid Search" "Referral" "Social"levels(fct_relevel(channel, "Referral", after = 2))## [1] "(Other)" "Affiliates" "Referral" "Direct"
## [5] "Display" "Organic Search" "Paid Search" "Social"Make Display the last level
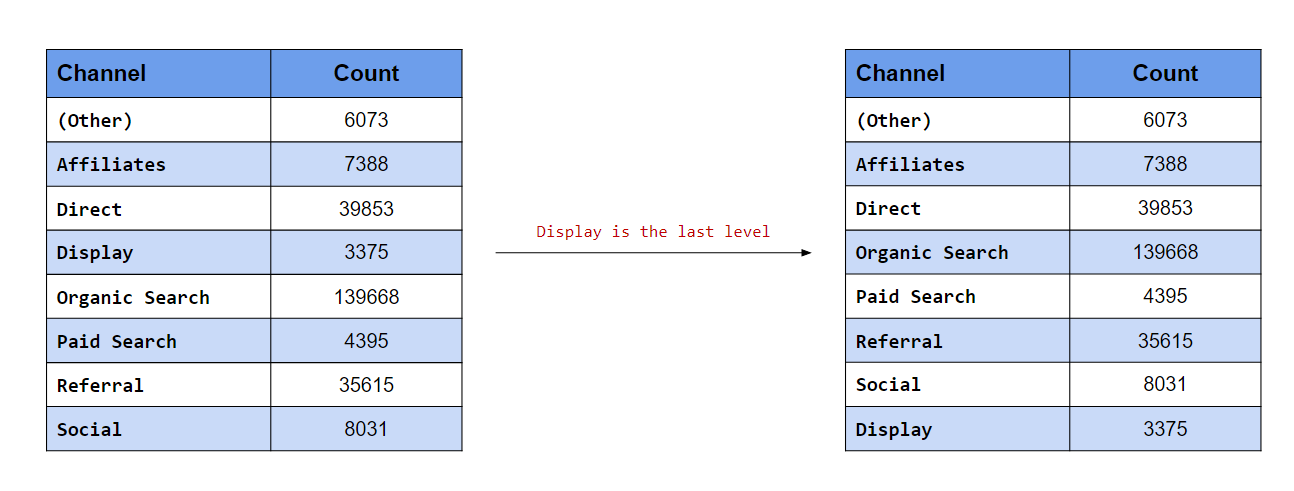
In this last case, we want to move Display to the end. If you know the number of levels, you can specify a value here. In our data, there are eight channels i.e. eight levels, so we can set the value of after to 7. What happens when we do not know the number of levels or if they tend to vary? In such cases, to move a level to the end, set the value of after to Inf.
levels(channel)## [1] "(Other)" "Affiliates" "Direct" "Display"
## [5] "Organic Search" "Paid Search" "Referral" "Social"levels(fct_relevel(channel, "Display", after = Inf))## [1] "(Other)" "Affiliates" "Direct" "Organic Search"
## [5] "Paid Search" "Referral" "Social" "Display"Let us now look at a scenario where we want to order the levels by
- frequency (largest to smallest)
- order of appearance (in data)
Order levels by frequency
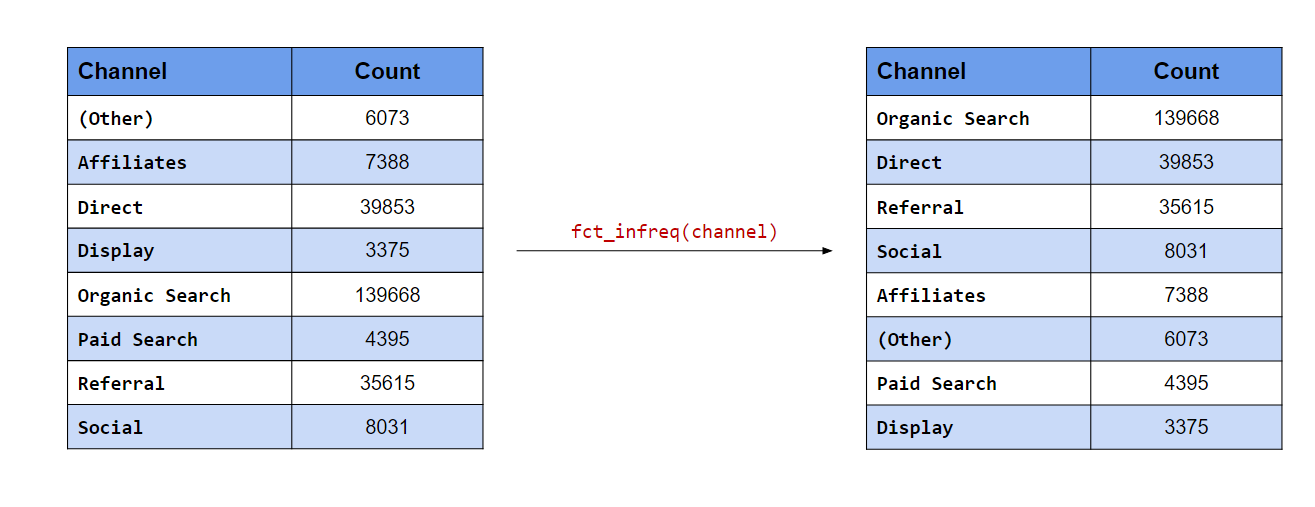
In the first case, the levels with the most frequency should appear at the top. fct_infreq() will order the
levels by their frequency.
# reorder levels
levels(channel)## [1] "(Other)" "Affiliates" "Direct" "Display"
## [5] "Organic Search" "Paid Search" "Referral" "Social"levels(fct_infreq(channel))## [1] "Organic Search" "Direct" "Referral" "Social"
## [5] "Affiliates" "(Other)" "Paid Search" "Display"Order levels by appearance

In the second case, the order of the levels should be the same as the order of their appearance in the data. fct_inorder() will order the levels according to the order in which they appear in the data.
# reorder levels
levels(channel)## [1] "(Other)" "Affiliates" "Direct" "Display"
## [5] "Organic Search" "Paid Search" "Referral" "Social"levels(fct_inorder(channel))## [1] "Organic Search" "Direct" "Referral" "Affiliates"
## [5] "(Other)" "Social" "Display" "Paid Search"Reverse the order of the levels
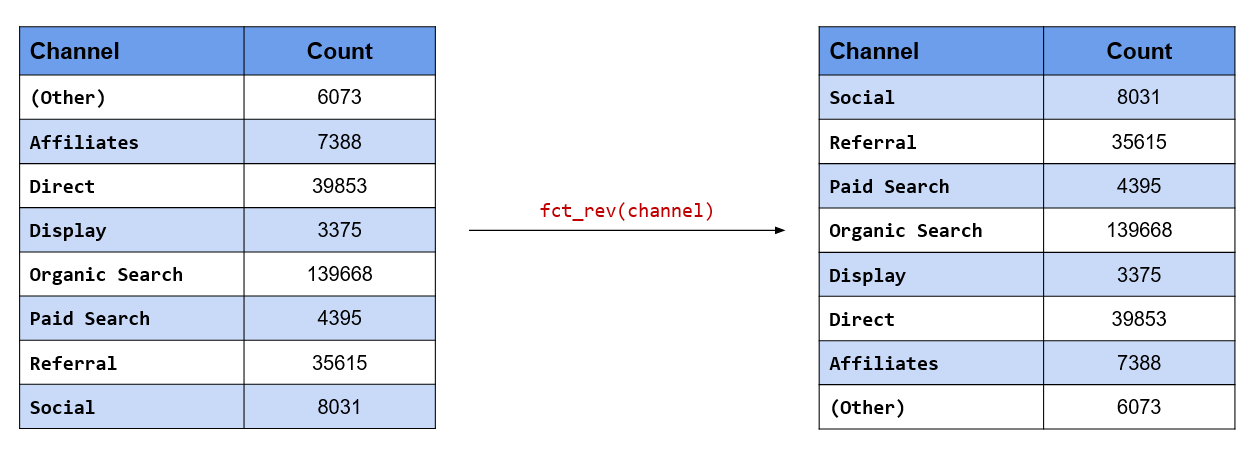
The order of the levels can be reversed using fct_rev().
# reorder levels
levels(channel)## [1] "(Other)" "Affiliates" "Direct" "Display"
## [5] "Organic Search" "Paid Search" "Referral" "Social"levels(fct_rev(channel))## [1] "Social" "Referral" "Paid Search" "Organic Search"
## [5] "Display" "Direct" "Affiliates" "(Other)"Randomly shuffle the order of the levels

The order of the levels can be randomly shuffled using fct_shuffle().
# reorder levels
levels(channel)## [1] "(Other)" "Affiliates" "Direct" "Display"
## [5] "Organic Search" "Paid Search" "Referral" "Social"levels(fct_shuffle(channel))## [1] "Organic Search" "Referral" "Display" "(Other)"
## [5] "Direct" "Paid Search" "Affiliates" "Social"Key Functions
| Function | Description |
|---|---|
fct_relevel()
|
Reorder factor levels |
fct_shift()
|
Shift factor levels |
fct_infreq()
|
Reorder factor levels by frequency |
fct_rev()
|
Reverse order of factor levels |
fct_inorder()
|
Reorder factor levels by first appearance |
fct_shuffle()
|
Randomly shuffle factor levels |
Your Turn…
Display the count/frequency of the following variables in the descending order
devicelanding_pageexit_page
Check if
laptopis a level in thedevicecolumn.Combine the following levels in
landing_pageintoAccountMy AccountRegisterSign InYour Info
Combine levels in
landing_pagethat drive less than 1000 visits.Get top 10 landing and exit pages.
Get landing pages that drive at least 5% of the total traffic to the website.
Retain only the following levels in the
browsercolumn:ChromeFirefoxSafariEdge
Anonymize landing and exit page levels.
Make
Homefirst level in thelanding_pagecolumn.Make
Apparelsecond level in thelanding_pagecolumn.Make
Specialslast level in thelanding_pagecolumn.Order the levels in the browser by frequency:
Order the levels in landing page by appearance:
Shuffle the levels in os
Reverse the levels in browser
*As the reader of this blog, you are our most important critic and commentator. We value your opinion and want to know what we are doing right, what we could do better, what areas you would like to see us publish in, and any other words of wisdom you are willing to pass our way.
We welcome your comments. You can email to let us know what you did or did not like about our blog as well as what we can do to make our post better.*
Email: support@rsquaredacademy.com