
This is part 1 of a series on “Handling Categorical Data in R.” Almost every data science project involves working with categorical data, and we should know how to read, store, summarize, reshape & visualize such data. Working with categorical data is different from working with other data types such as numbers or text. In this article, we will understand what categorical data is, how R stores it using factor, and explore the rich set of functions (built-in & through packages) provided by R for working with such data. Throughout the series, we will also work through a case study to better understand the concepts we learn. Happy learning!
Below are the links to the other articles of this series:
- Part 2 - Summarize Categorical Data
- Part 3 - Reshape Categorical Data
- Part 4 - Visualize Categorical Data
Table of Contents
Resources
You can download all the data sets, R scripts, practice questions and their solutions from our GitHub repository.
Introduction
Before we begin our deep dive on categorical data, let us get a quick overview of different data types. Feel free to skip this section if you know the difference between nominal and ordinal data.
Data Types
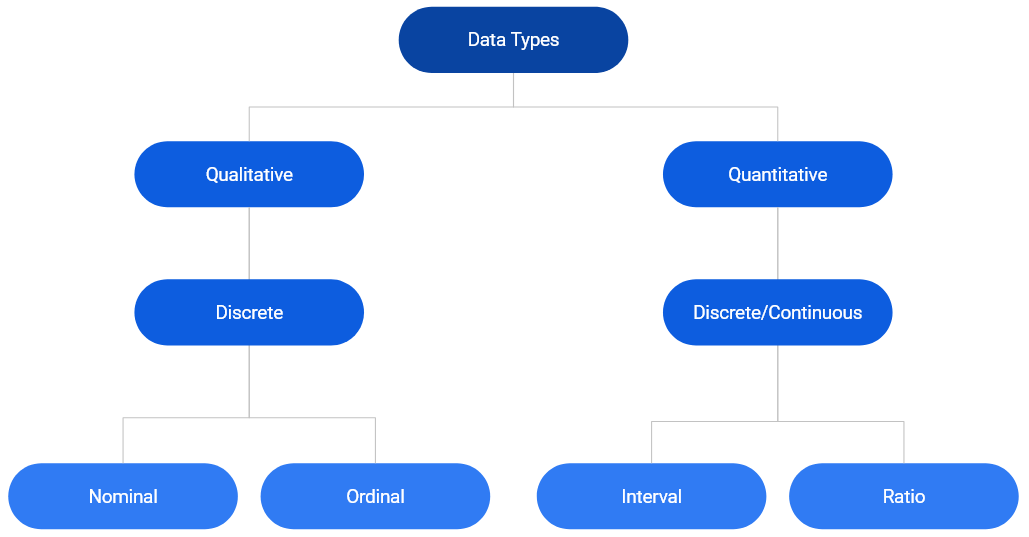
In the chart above, we can see that data can be primarily classified into qualitative or quantitative. (The word categorical is used interchangeably with qualitative throughout the series). Qualitative data consists of labels or names. Quantitative data, on the other hand, consists of numbers and indicate how much or how many. This brings us to the next level of classification:
- discrete
- continuous
In the chart, we can observe that qualitative data is always discrete where as quantitative data may be discrete or continuous. Qualitative data is further classified into
- nominal
- ordinal
First, we will understand discrete and continuous data, and then proceed to explore nominal and ordinal data.
Discrete Data

Discrete data arises in situations where counting is involved. It can take on only a finite number of values and cannot be divided into smaller parts. For example, let us consider the number of students in a class. We can have 5 0r 10 students but not 5.5 students (we can’t have half a student).
Continuous Data

Continuous data arises in situations where measuring is involved. It can take any numeric value in a specified range and can be divided into smaller parts and still have meaning. Examples include money, temperature, length, volume etc.
Categorical Data
Since our interest is in categorical data, we will spend more time understanding the different types of categorical data through various examples. Let us begin by formally defining categorical data:
- it is always discrete
- it may be divided into groups
- consists of names or labels
- takes on limited & fixed number of possible values
- arises in situation when counting is involved
- analysis generally involves the use of data tables
Dichotomous
A categorical variable that can take on exactly two values is termed as binary or dichotomous variable.

Polychotomous
Categorical variables with more than two possible values are called polychotomous variables.

Ordinal

In ordinal data, the categories can be ordered or ranked. Examples include
- socio-economic status
- education level
- income level
- satisfaction rating
While we can rank the categories, we cannot assign a value to them. For example, in satisfaction ranking, we cannot say that like is twice as positive as dislike i.e. we are unable to say how much they differ from each other. While the order or rank of data is meaningful, the difference between two pieces of data cannot be measured/determined or are meaningless. Ordinal data provide information about relative comparisons, but not the magnitude of the differences.
Nominal
![]()
Nominal data do not have an intrinsic order and cannot be ordered or measured. Examples include
- blood group
- gender
- religion
- color
Categorical data are sometimes coded with numbers, with those numbers replacing names. Although such numbers might appear to be quantitative, they are actually categorical data. When they do take numerical values, those numbers do not have any mathematical meaning. Examples include months expressed in numbers.
Case Study
As is the practice, throughout this series, we will work on a case study related to an e-commerce firm. As most of you would already be aware, a lot of data is captured when you go on the internet by the websites you browse as well as by third party cookies. Data collected is then used to display ads as well as to feed to recommendation algorithms.
The data used in the case study represents the basic information that is captured when users visit any website. It closely resembles real world data for an e-commerce store. We will try to generate insights about the visitors to be used by an imaginary marketing team for better targeting and promotion. The case study data set can be imported using the RStudio IDE or R code.
Data
The data set is available in both CSV & RDS formats.
CSV
If you want to specify the data types while reading the data, use the readr package. We have explored how to import data into R in a previous article. We will read a subset of columns from the data set (it has 20 columns) which will cover both nominal and ordinal data types. To import the data, we will use the read_csv() function. The first input is the name of the data set, analytics.csv. Ensure that the name is enclosed in single/double quotes.
read_csv("analytics_raw.csv",
col_types = cols_only(device = col_factor(levels = c("Desktop", "Tablet", "Mobile")),
gender = col_factor(levels = c("female", "male", "NA")),
user_rating = col_factor(levels = c("1", "2", "3", "4", "5"),
ordered = TRUE)))## New names:
## * `` -> ...1## # A tibble: 244,398 x 3
## device gender user_rating
## <fct> <fct> <ord>
## 1 Desktop female 4
## 2 Mobile NA 5
## 3 Desktop NA 4
## 4 Desktop NA 5
## 5 Desktop NA 4
## 6 Mobile NA 4
## 7 Desktop NA 4
## 8 Desktop NA 4
## 9 Desktop female 5
## 10 Desktop NA 4
## # ... with 244,388 more rowsSince we are specifying the column data types while importing the data, we will use the col_types
argument to list out the data types. As we are reading in a subset of the columns and not all of them,
we will use the cols_only() function indicating that only the columns specified must be read in and not
all of them.
Categorical data and the levels/groups are specified using the col_factor() function. Use the
levels argument to specify the levels/groups and the ordered argument to indicate if the data is ordinal. By default, it is set to FALSE, change this to TRUE if the column is ordinal.
RDS
The .rds file can be read using readRDS().
data <- readRDS('analytics.rds')
head(data)## # A tibble: 6 x 19
## device os browser user_type channel gender frequency recency page_depth
## <fct> <fct> <fct> <fct> <fct> <fct> <dbl> <dbl> <dbl>
## 1 Desktop Windows Chrome New Visi~ Organi~ female 1 0 1
## 2 Mobile iOS Safari Returnin~ Organi~ <NA> 3 1 1
## 3 Desktop Chrome OS Chrome New Visi~ Direct <NA> 1 0 5
## 4 Desktop Macintosh Chrome Returnin~ Organi~ <NA> 2 0 1
## 5 Desktop Macintosh Chrome Returnin~ Referr~ <NA> 5 8 1
## 6 Mobile Android Chrome New Visi~ Organi~ <NA> 1 0 5
## # ... with 10 more variables: hour_of_day <chr>, age <dbl>, duration <dbl>,
## # landing_page <fct>, exit_page <fct>, country <fct>, quantity <dbl>,
## # revenue <dbl>, purchase_flag <lgl>, user_rating <dbl>Data Dictionary
| Column | Description |
|---|---|
| device | Device used to browse the website |
| os | Operating system of the device |
| browser | Browser used to visit the website |
| user_type | New or returning visitor |
| channel | Source of traffic |
| gender | Gender of the visitor |
| frequency | Count of visits to the website |
| recency | Number of days since last visit |
| page_depth | Number of website pages browsed |
| hour_of_day | Hour of day |
| age | Age of the visitor |
| duration | Time spent on the website (in seconds) |
| landing_page | Page on which visitor landed |
| exit_page | Page on which visitor exited |
| country | Country of origin |
| city | City of the visitor |
| quantity | Number of units purchased |
| revenue | Total revenue |
| purchase_flag | Whether the visitor checked out? |
| user_rating | Website UI rating given by visitor |
Now that we have an overview of the case study, let us move on to the next section where we explore how R stores categorical data using factors.
Factors
In this very important section, we will learn how R
- stores categorical data
- checks if given data is categorical
- converts other data types to factor
- handles missing values in categorical data
- specifies the orders of the categories/levels
- stores ordinal data
In R, categorical data is stored as factor. Before we explore the factor family of functions, let us generate the sample data we will use in this module. We will generate the device column from the case study data set using the sample() function. We provide the following inputs to generate the data:
- values from which the data must be generated
- the size of the sample
- indicate if the values must be repeated (TRUE/FALSE)
device <- sample(c("Desktop", "Mobile", "Tablet"), size = 25, replace = TRUE)
device## [1] "Mobile" "Mobile" "Tablet" "Mobile" "Mobile" "Mobile" "Tablet"
## [8] "Tablet" "Desktop" "Mobile" "Mobile" "Mobile" "Tablet" "Mobile"
## [15] "Desktop" "Tablet" "Desktop" "Mobile" "Mobile" "Tablet" "Desktop"
## [22] "Mobile" "Tablet" "Mobile" "Mobile"Membership Testing
Great! We have successfully generated the sample data and along the way learnt a new R function for sampling. First, let us check if the sample is a factor using the membership function is.factor().
is.factor(device)## [1] FALSEMembership testing functions always have the prefix is_ and return only logical values. If the object is a member of the specified class, they return TRUE else FALSE. Since our sample data is not stored as a factor, R has returned FALSE.
Coercion
Let us try to coerce it into factor using the coercion function as.factor().
as.factor(device)## [1] Mobile Mobile Tablet Mobile Mobile Mobile Tablet Tablet Desktop
## [10] Mobile Mobile Mobile Tablet Mobile Desktop Tablet Desktop Mobile
## [19] Mobile Tablet Desktop Mobile Tablet Mobile Mobile
## Levels: Desktop Mobile TabletDo you spot any difference in the output? In the last line, it displays the levels or categories of the variable. Don’t worry if you didn’t spot it. We are just getting started and you will pick it up by the end of this section. Another function that can be used to coerce data into factor is as_factor() from the forcats package.
as_factor(device)## [1] Mobile Mobile Tablet Mobile Mobile Mobile Tablet Tablet Desktop
## [10] Mobile Mobile Mobile Tablet Mobile Desktop Tablet Desktop Mobile
## [19] Mobile Tablet Desktop Mobile Tablet Mobile Mobile
## Levels: Mobile Tablet DesktopDid you notice any difference between these two functions? Focus on the last line of the output where the
levels are displayed. Now observe the order of the levels. as.factor() displays levels in the alphabetical order whereas as_factor() displays them in order of appearance in the data. Mobile, followed by Tablet, and then Desktop. If you look at the data, they appear in the same order.
Factor Function
If you want finer control while creating factors, use the factor() function. as.factor() should suffice in most cases but use factor() when you want to:
- specify levels
- modify labels
- include
NAas a level/category - create ordered factors
- specify order of levels
The first input is a vector, usually a numeric or character vector with a small number of unique values. In our example, it is a character vector of length 25 (i.e. 25 values) but 3 unique values.
factor(device)## [1] Mobile Mobile Tablet Mobile Mobile Mobile Tablet Tablet Desktop
## [10] Mobile Mobile Mobile Tablet Mobile Desktop Tablet Desktop Mobile
## [19] Mobile Tablet Desktop Mobile Tablet Mobile Mobile
## Levels: Desktop Mobile TabletIf you want to specify the levels or categories, use the levels argument.
factor(device, levels = c("Desktop", "Mobile", "Tablet"))## [1] Mobile Mobile Tablet Mobile Mobile Mobile Tablet Tablet Desktop
## [10] Mobile Mobile Mobile Tablet Mobile Desktop Tablet Desktop Mobile
## [19] Mobile Tablet Desktop Mobile Tablet Mobile Mobile
## Levels: Desktop Mobile TabletLevels not specified will be replaced by NA. Let us specify only Desktop and Mobile as the levels in the device column and see what happens.
factor(device, levels = c("Desktop", "Mobile"))## [1] Mobile Mobile <NA> Mobile Mobile Mobile <NA> <NA> Desktop
## [10] Mobile Mobile Mobile <NA> Mobile Desktop <NA> Desktop Mobile
## [19] Mobile <NA> Desktop Mobile <NA> Mobile Mobile
## Levels: Desktop MobileAs you can see, Tablet has been replaced by NA.
Modify Labels
You can change the labels of the levels using the labels argument. The labels must be in the same order as the levels. We will modify the labels to Desk, Mob & Tab for Desktop, Mobile & Tablet respectively.
factor(device,
levels = c("Desktop", "Mobile", "Tablet"),
labels = c("Desk", "Mob", "Tab"))## [1] Mob Mob Tab Mob Mob Mob Tab Tab Desk Mob Mob Mob Tab Mob Desk
## [16] Tab Desk Mob Mob Tab Desk Mob Tab Mob Mob
## Levels: Desk Mob TabYou can see that not only the values but the levels are also modified.
Missing Values
Let us regenerate the device column but include some missing values (NA) deliberately to see how factor() handles them.
# sample with missing values
device <- sample(c("Desktop", "Mobile", "Tablet", NA), size = 25, replace = TRUE)
device## [1] "Desktop" "Tablet" "Tablet" NA "Mobile" NA "Desktop"
## [8] "Desktop" "Tablet" "Mobile" "Tablet" "Desktop" "Desktop" "Mobile"
## [15] NA "Desktop" "Mobile" "Tablet" "Mobile" "Mobile" "Tablet"
## [22] NA "Desktop" "Tablet" "Mobile"# store as categorical data
factor(device)## [1] Desktop Tablet Tablet <NA> Mobile <NA> Desktop Desktop Tablet
## [10] Mobile Tablet Desktop Desktop Mobile <NA> Desktop Mobile Tablet
## [19] Mobile Mobile Tablet <NA> Desktop Tablet Mobile
## Levels: Desktop Mobile TabletNA is not shown as one of the levels. Why does this happen? By default, it will ignore them. If you look
at the arguments of the factor() function, the exclude argument is set to NA by default i.e. NA is excluded automatically. What should we do to ensure that NA is also treated as a level? In order to treat NA as a level, set the exclude argument to NULL.
factor(device, exclude = NULL)## [1] Desktop Tablet Tablet <NA> Mobile <NA> Desktop Desktop Tablet
## [10] Mobile Tablet Desktop Desktop Mobile <NA> Desktop Mobile Tablet
## [19] Mobile Mobile Tablet <NA> Desktop Tablet Mobile
## Levels: Desktop Mobile Tablet <NA>As you can see, NA is displayed as one of the levels in the data.
Ordered Factors
So far, we have been looking at nominal data. Let us now explore how R handles ordered data. We will generate a new data set of satisfaction ratings to use in this section. Satisfaction ratings are widely used to measure a customer’s satisfaction with an organization, service or a product.
rating <- sample(c("Dislike", "Neutral", "Like"), size = 25, replace = TRUE)
rating## [1] "Like" "Dislike" "Neutral" "Dislike" "Neutral" "Like" "Neutral"
## [8] "Dislike" "Dislike" "Dislike" "Dislike" "Neutral" "Dislike" "Neutral"
## [15] "Dislike" "Dislike" "Like" "Neutral" "Dislike" "Neutral" "Like"
## [22] "Neutral" "Dislike" "Like" "Dislike"It consists of three values Dislike, Neutral & Like in that order. You can see that there is an intrinsic order here. Like is better than neutral which in turn is better than dislike. While we can order them, we can’t quantify the difference between them. We can’t say neutral is so many times better than dislike.
Membership Testing
As we did earlier, let us check if the data is ordered using the membership function is.ordered().
is.ordered(rating)## [1] FALSER returns FALSE as the variable rating is not ordered. Let us use as.ordered() to coerce it into an ordered factor.
as.ordered(rating)## [1] Like Dislike Neutral Dislike Neutral Like Neutral Dislike Dislike
## [10] Dislike Dislike Neutral Dislike Neutral Dislike Dislike Like Neutral
## [19] Dislike Neutral Like Neutral Dislike Like Dislike
## Levels: Dislike < Like < NeutralLook at the last line where the levels are displayed. In case of ordered factors, you will see a < between the labels. This is used to indicate the order of the levels. Now rating is both an ordered but the order of the levels is not correct. It should be Dislike < Neutral < Like but is displayed in order of appearance in the data. Let us use the factor() function since we need more control over how the levels are ranked and set the ordered argument to TRUE.
factor(rating, ordered = TRUE)## [1] Like Dislike Neutral Dislike Neutral Like Neutral Dislike Dislike
## [10] Dislike Dislike Neutral Dislike Neutral Dislike Dislike Like Neutral
## [19] Dislike Neutral Like Neutral Dislike Like Dislike
## Levels: Dislike < Like < NeutralThe ranking of the levels has not changed and is still the same. Why is this happening? If you observe carefully, the ranking follows the alphabetical order (Desktop, Mobile, Table). The factor() function uses the same order for the levels.
Modify Order of Levels
To change the order/ranking of the levels, we need to specify it using the levels argument. Let us do that in the next example.
factor(rating, levels = c("Dislike", "Neutral", "Like"), ordered = TRUE)## [1] Like Dislike Neutral Dislike Neutral Like Neutral Dislike Dislike
## [10] Dislike Dislike Neutral Dislike Neutral Dislike Dislike Like Neutral
## [19] Dislike Neutral Like Neutral Dislike Like Dislike
## Levels: Dislike < Neutral < LikeNow, you can see that the levels are ranked correctly. The ordered() function can also be used to create ordered factors. Let us recreate the previous example using the ordered() function.
ordered(rating, levels = c("Dislike", "Neutral", "Like"))## [1] Like Dislike Neutral Dislike Neutral Like Neutral Dislike Dislike
## [10] Dislike Dislike Neutral Dislike Neutral Dislike Dislike Like Neutral
## [19] Dislike Neutral Like Neutral Dislike Like Dislike
## Levels: Dislike < Neutral < LikeYou can specify levels, modify labels and handle missing values using the ordered() function as well.
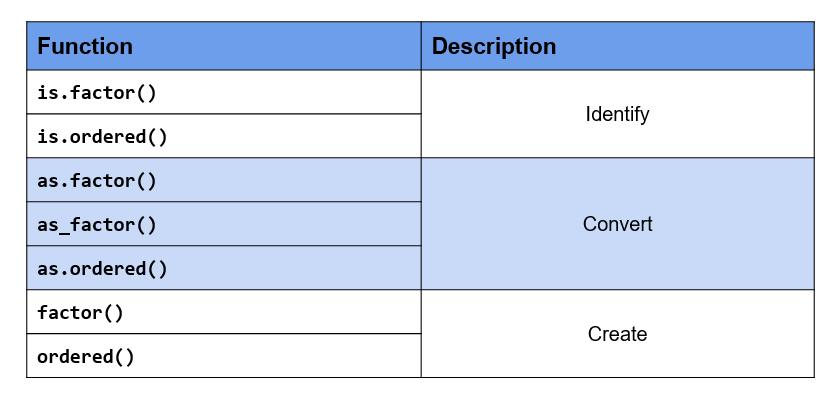
Key Functions
Summary
- R uses factor to handle categorical data.
- Use
as.factor()oras_factor()to coerce other data types to factor. - Use
is.factor()oris.ordered()to identify factor & ordered factor respectively. - Use
factor()to- specify labels
- modify labels
- handle missing data
- create ordered factors
- specify order of levels
- Use
ordered()to create ordered factors.
Your Turn…
Use analytics_raw.rds data set to answer the below questions.
Check whether the below variables are factor
devicepage_depthlanding_page
Coerce the following variables to type factor
deviceosbrowseruser_typechannelgenderlanding_pageexit_pagecitycountryuser_type
Use only the following levels in the
gendercolumn:malefemale
Include
NAas a level in the gender column.Change label of
NAtomissingin thegendercolumn.Change the labels of the levels in
user_typecolumn toNewReturning
Check if the
user_ratingcolumn is ordered. If not, coerce it to type ordered factor.
*As the reader of this blog, you are our most important critic and commentator. We value your opinion and want to know what we are doing right, what we could do better, what areas you would like to see us publish in, and any other words of wisdom you are willing to pass our way.
We welcome your comments. You can email to let us know what you did or did not like about our blog as well as what we can do to make our post better.*
Email: support@rsquaredacademy.com