Introduction
In the previous post, we learnt to combine tables using dplyr. In this post, we will explore a set of helper functions in order to:
- extract unique rows
- rename columns
- sample data
- extract columns
- slice rows
- arrange rows
- compare tables
- extract/mutate data using predicate functions
- count observations for different levels of a variable
Libraries, Code & Data
We will use the following packages:
The data sets can be downloaded from here and the codes from here.
library(dplyr)
library(readr)Case Study
Let us look at a case study (e-commerce data) and see how we can use dplyr helper functions to answer questions we have about and to modify/transform the underlying data set.
Data
ecom <-
read_csv('https://raw.githubusercontent.com/rsquaredacademy/datasets/master/web.csv',
col_types = cols_only(device = col_factor(levels = c("laptop", "tablet", "mobile")),
referrer = col_factor(levels = c("bing", "direct", "social", "yahoo", "google")),
purchase = col_logical(), bouncers = col_logical(), duration = col_double(),
n_visit = col_double(), n_pages = col_double()
)
)
ecom## # A tibble: 1,000 x 7
## referrer device bouncers n_visit n_pages duration purchase
## <fct> <fct> <lgl> <dbl> <dbl> <dbl> <lgl>
## 1 google laptop TRUE 10 1 693 FALSE
## 2 yahoo tablet TRUE 9 1 459 FALSE
## 3 direct laptop TRUE 0 1 996 FALSE
## 4 bing tablet FALSE 3 18 468 TRUE
## 5 yahoo mobile TRUE 9 1 955 FALSE
## 6 yahoo laptop FALSE 5 5 135 FALSE
## 7 yahoo mobile TRUE 10 1 75 FALSE
## 8 direct mobile TRUE 10 1 908 FALSE
## 9 bing mobile FALSE 3 19 209 FALSE
## 10 google mobile TRUE 6 1 208 FALSE
## # ... with 990 more rowsData Dictionary
- referrer: referrer website/search engine
- device: device used to visit the website
- bouncers: whether a visit bounced (exited from landing page)
- duration: time spent on the website (in seconds)
- purchase: whether visitor purchased
- n_visit: number of visits
- n_pages: number of pages visited/browsed
Data Sanitization
Let us ensure that the data is sanitized by checking the sources of traffic
and devices used to visit the site. We will use distinct to examine the
values in the referrer column
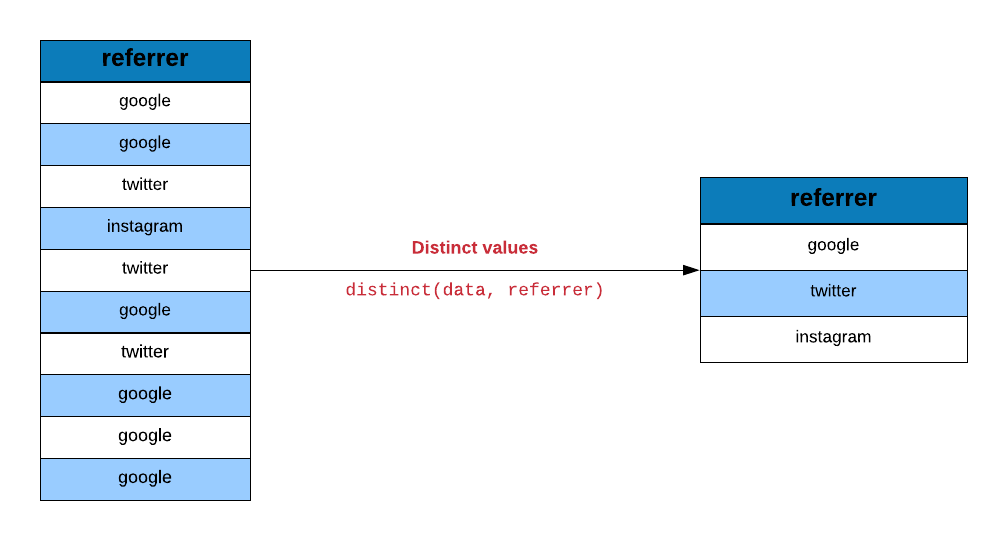
distinct(ecom, referrer)## # A tibble: 5 x 1
## referrer
## <fct>
## 1 google
## 2 yahoo
## 3 direct
## 4 bing
## 5 socialand the device column as well.
distinct(ecom, device)## # A tibble: 3 x 1
## device
## <fct>
## 1 laptop
## 2 tablet
## 3 mobileRename Columns
Columns can be renamed using rename().

rename(ecom, time_on_site = duration)## # A tibble: 1,000 x 7
## referrer device bouncers n_visit n_pages time_on_site purchase
## <fct> <fct> <lgl> <dbl> <dbl> <dbl> <lgl>
## 1 google laptop TRUE 10 1 693 FALSE
## 2 yahoo tablet TRUE 9 1 459 FALSE
## 3 direct laptop TRUE 0 1 996 FALSE
## 4 bing tablet FALSE 3 18 468 TRUE
## 5 yahoo mobile TRUE 9 1 955 FALSE
## 6 yahoo laptop FALSE 5 5 135 FALSE
## 7 yahoo mobile TRUE 10 1 75 FALSE
## 8 direct mobile TRUE 10 1 908 FALSE
## 9 bing mobile FALSE 3 19 209 FALSE
## 10 google mobile TRUE 6 1 208 FALSE
## # ... with 990 more rowsData Tabulation
Let us now look at the proportion or share of visits driven by different sources of traffic.
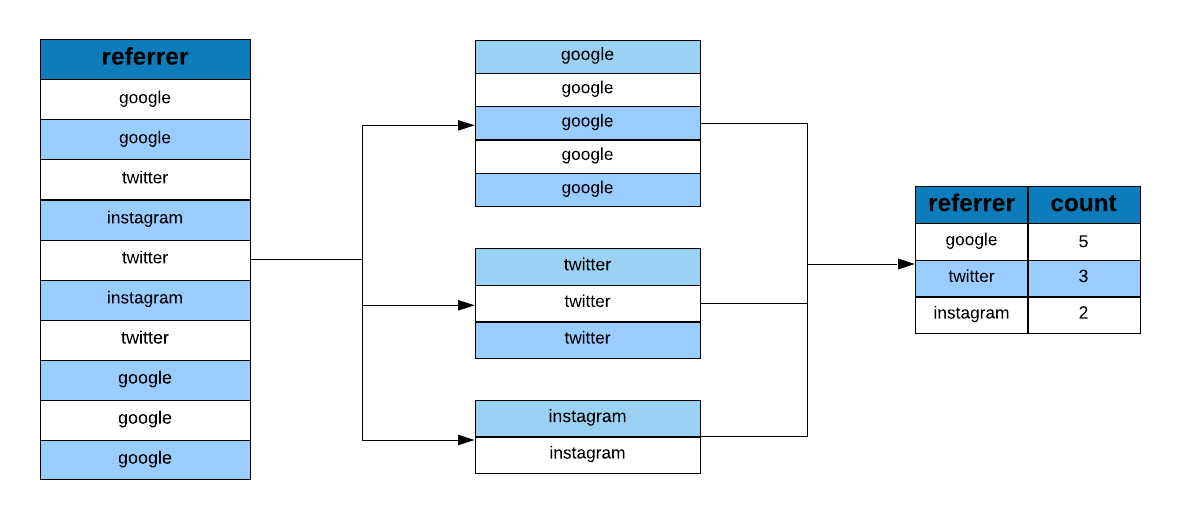
ecom %>%
group_by(referrer) %>%
tally()## # A tibble: 5 x 2
## referrer n
## * <fct> <int>
## 1 bing 194
## 2 direct 191
## 3 social 200
## 4 yahoo 207
## 5 google 208We would also like to know the number of bouncers driven by the different sources of traffic.
ecom %>%
group_by(referrer, bouncers) %>%
tally()## # A tibble: 10 x 3
## # Groups: referrer [5]
## referrer bouncers n
## <fct> <lgl> <int>
## 1 bing FALSE 104
## 2 bing TRUE 90
## 3 direct FALSE 98
## 4 direct TRUE 93
## 5 social FALSE 93
## 6 social TRUE 107
## 7 yahoo FALSE 110
## 8 yahoo TRUE 97
## 9 google FALSE 101
## 10 google TRUE 107Let us look at how many conversions happen across different devices.
ecom %>%
group_by(device, purchase) %>%
tally() %>%
filter(purchase)## # A tibble: 3 x 3
## # Groups: device [3]
## device purchase n
## <fct> <lgl> <int>
## 1 laptop TRUE 31
## 2 tablet TRUE 36
## 3 mobile TRUE 36Another way to extract the above information is by using count
ecom %>%
count(referrer, purchase) %>%
filter(purchase)## # A tibble: 5 x 3
## referrer purchase n
## <fct> <lgl> <int>
## 1 bing TRUE 17
## 2 direct TRUE 25
## 3 social TRUE 20
## 4 yahoo TRUE 22
## 5 google TRUE 19Sampling Data
dplyr offers sampling functions which allow us to specify either the
number or percentage of observations. sample_n() allows sampling a specific
number of observations.

sample_n(ecom, 700)## # A tibble: 700 x 7
## referrer device bouncers n_visit n_pages duration purchase
## <fct> <fct> <lgl> <dbl> <dbl> <dbl> <lgl>
## 1 yahoo laptop FALSE 2 9 162 FALSE
## 2 yahoo tablet FALSE 2 14 364 TRUE
## 3 social laptop TRUE 1 1 111 FALSE
## 4 direct laptop TRUE 4 1 896 FALSE
## 5 yahoo mobile FALSE 5 8 80 FALSE
## 6 social laptop TRUE 0 1 720 FALSE
## 7 bing mobile TRUE 5 1 190 FALSE
## 8 direct mobile TRUE 2 1 501 FALSE
## 9 yahoo tablet TRUE 1 1 605 FALSE
## 10 bing laptop TRUE 1 1 169 FALSE
## # ... with 690 more rowsWe can combine the sampling functions with other dplyr functions as shown below where we sample observation after grouping them according to the source of traffic.
ecom %>%
group_by(referrer) %>%
sample_n(100)## # A tibble: 500 x 7
## # Groups: referrer [5]
## referrer device bouncers n_visit n_pages duration purchase
## <fct> <fct> <lgl> <dbl> <dbl> <dbl> <lgl>
## 1 bing mobile FALSE 3 8 120 FALSE
## 2 bing laptop FALSE 9 13 299 FALSE
## 3 bing tablet FALSE 2 17 510 FALSE
## 4 bing laptop TRUE 9 1 709 FALSE
## 5 bing tablet TRUE 0 1 845 FALSE
## 6 bing tablet TRUE 1 1 721 FALSE
## 7 bing tablet TRUE 0 1 425 FALSE
## 8 bing mobile FALSE 0 7 196 FALSE
## 9 bing tablet TRUE 4 1 493 FALSE
## 10 bing mobile TRUE 6 1 604 FALSE
## # ... with 490 more rowssample_frac() allows a specific percentage of observations.
sample_frac(ecom, size = 0.7)## # A tibble: 700 x 7
## referrer device bouncers n_visit n_pages duration purchase
## <fct> <fct> <lgl> <dbl> <dbl> <dbl> <lgl>
## 1 google mobile TRUE 0 1 132 FALSE
## 2 yahoo tablet TRUE 7 1 889 FALSE
## 3 bing mobile FALSE 7 1 22 FALSE
## 4 google laptop TRUE 5 1 376 FALSE
## 5 social tablet FALSE 10 11 330 TRUE
## 6 social mobile FALSE 7 8 216 FALSE
## 7 bing mobile FALSE 1 12 168 FALSE
## 8 bing tablet TRUE 7 1 489 FALSE
## 9 social laptop TRUE 0 1 581 FALSE
## 10 direct laptop FALSE 6 6 96 FALSE
## # ... with 690 more rowsData Extraction
In the first post, we had observed that dplyr verbs always returned a tibble. What if you want to extract a specific column or a bunch of rows but not as a tibble?
Use pull to extract columns either by name or position. It will return a
vector. In the below example, we extract the device column as a vector. I am
using head in addition to limit the output printed.
Sample Data
ecom_mini <- sample_n(ecom, size = 10)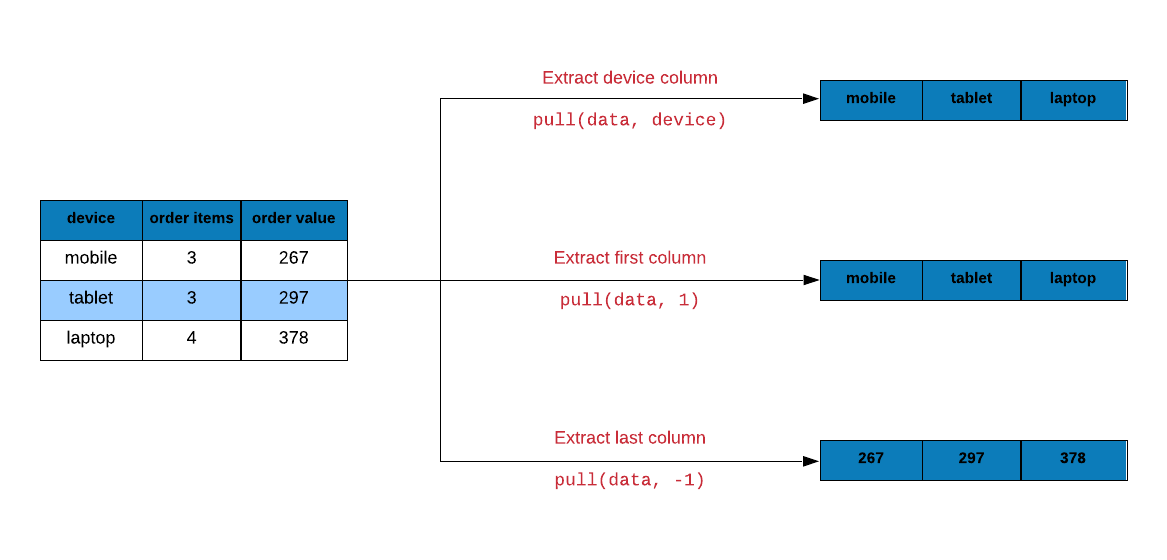
pull(ecom_mini, device)## [1] laptop mobile mobile laptop tablet laptop mobile laptop tablet tablet
## Levels: laptop tablet mobileLet us extract the first column from ecom using column position instead of
name.
pull(ecom_mini, 1) ## [1] bing google yahoo direct bing direct bing bing bing bing
## Levels: bing direct social yahoo googleYou can use - before the column position to indicate the position in reverse.
The below example extracts data from the last column.
pull(ecom_mini, -1) ## [1] FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSELet us now look at extracting rows using slice(). In the below example, we
extract data starting from the 5th row and upto the 15th row.
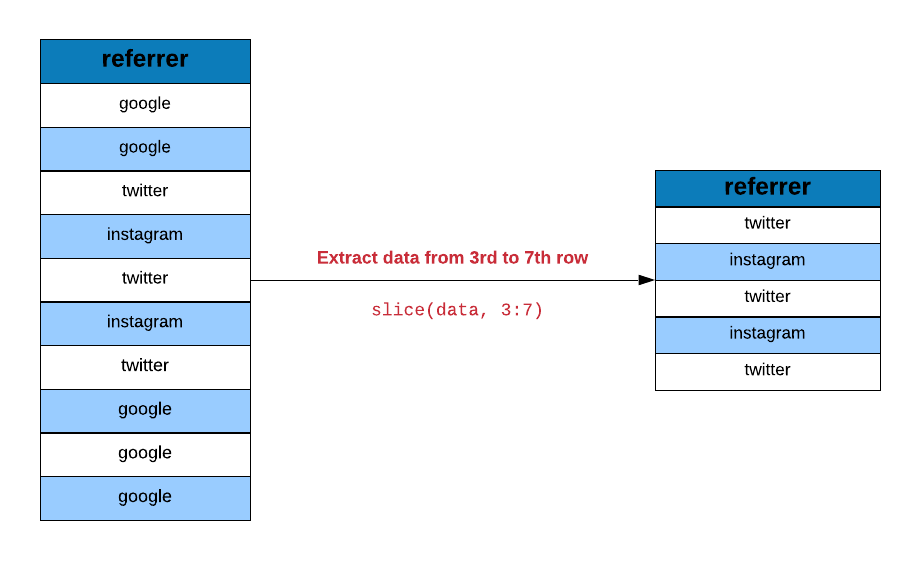
slice(ecom, 5:15)## # A tibble: 11 x 7
## referrer device bouncers n_visit n_pages duration purchase
## <fct> <fct> <lgl> <dbl> <dbl> <dbl> <lgl>
## 1 yahoo mobile TRUE 9 1 955 FALSE
## 2 yahoo laptop FALSE 5 5 135 FALSE
## 3 yahoo mobile TRUE 10 1 75 FALSE
## 4 direct mobile TRUE 10 1 908 FALSE
## 5 bing mobile FALSE 3 19 209 FALSE
## 6 google mobile TRUE 6 1 208 FALSE
## 7 direct laptop TRUE 9 1 738 FALSE
## 8 direct tablet FALSE 6 12 132 FALSE
## 9 direct mobile FALSE 9 14 406 TRUE
## 10 yahoo tablet FALSE 5 8 80 FALSE
## 11 yahoo mobile FALSE 7 1 19 FALSEUse n() inside slice() to extract the last row.
slice(ecom, n())## # A tibble: 1 x 7
## referrer device bouncers n_visit n_pages duration purchase
## <fct> <fct> <lgl> <dbl> <dbl> <dbl> <lgl>
## 1 google mobile TRUE 9 1 269 FALSEBetween
between() allows us to test if the values in a column lie between two specific
values. In the below example, we check how many visits browsed pages between 5
and 15.
ecom_sample <- sample_n(ecom, 30)
ecom_sample %>%
pull(n_pages) %>%
between(5, 15) ## [1] FALSE FALSE FALSE TRUE TRUE FALSE FALSE FALSE FALSE TRUE TRUE FALSE
## [13] TRUE TRUE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE
## [25] FALSE FALSE FALSE FALSE FALSE FALSECase When
case_when() is an alternative to if else. It allows us to lay down the
conditions clearly and makes the code more readable. In the below example, we
create a new column repeat_visit from n_visit (the number of previous visits).
ecom %>%
mutate(
repeat_visit = case_when(
n_visit > 0 ~ TRUE,
TRUE ~ FALSE
)
) %>%
select(n_visit, repeat_visit) ## # A tibble: 1,000 x 2
## n_visit repeat_visit
## <dbl> <lgl>
## 1 10 TRUE
## 2 9 TRUE
## 3 0 FALSE
## 4 3 TRUE
## 5 9 TRUE
## 6 5 TRUE
## 7 10 TRUE
## 8 10 TRUE
## 9 3 TRUE
## 10 6 TRUE
## # ... with 990 more rows